First we need to load the penguin data set, just like we have before. The data set will be called penguins This data was collected by real scientists! Data were collected and made available by Dr. Kristen Gorman and the Palmer Station, Antarctica LTER, a member of the Long Term Ecological Research Network.
# A tibble: 344 × 8
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<fct> <fct> <dbl> <dbl> <int> <int>
1 Adelie Torgersen 39.1 18.7 181 3750
2 Adelie Torgersen 39.5 17.4 186 3800
3 Adelie Torgersen 40.3 18 195 3250
4 Adelie Torgersen NA NA NA NA
5 Adelie Torgersen 36.7 19.3 193 3450
6 Adelie Torgersen 39.3 20.6 190 3650
7 Adelie Torgersen 38.9 17.8 181 3625
8 Adelie Torgersen 39.2 19.6 195 4675
9 Adelie Torgersen 34.1 18.1 193 3475
10 Adelie Torgersen 42 20.2 190 4250
# ℹ 334 more rows
# ℹ 2 more variables: sex <fct>, year <int>
library(tidyverse) # to make tidyverse commands available
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
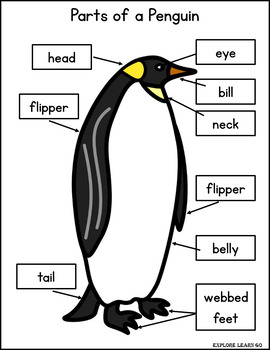
There are three different species of penguins in this data set. We can see from the photo below that they may have different body dimensions. We will be using data visualizations to explore some of these differences.
Remember
Create a histogram of body mass for all penguin species. Using comments, write a description of what this histogram shows.
Create a histogram of body mass, with each species in a different color. What does this show us about the different species? Which species do you think has the greatest body mass?
Now let’s find out! Create a bar graph with the average body mass for each penguin species. (Don’t forget about the NAs in the data set) Which one has the greatest average body mass? How does that compare with what you thought looking at the histogram?
Create a visualization that will help answer the question: Do heavier penguins have longer flippers? Think about how many variables you have and the best way to present this data. Color by species.
Create a data visualization to explore the question: Do penguins with longer bills tend to have longer flippers as well? Make sure to give the points either different colors or shapes based on the species.
Create a bar graph that shows the average body mass by sex.
Create one figure that has three bar graphs: comparing average body mass by sex AND species. If you need a hint, please ask!
Think about how many variables you are graphing (one or two), what kind of variables they are (categorical or numerical), and what question your viz will explore!
Create a a pie chart, showing the percentage of the data set each penguin species comprises. (you definitely will need to use google). In data science, are pie charts a good idea? Take a look here, and explain your answer.